MANUAL EJECUCIÓN SCRIPTS DE CARGUE
INDICE
- Recursos necesarios.
- Vistas utilizadas para el cargue e instancia de los elementos.
- Explorador de entidades.
- Carga masiva de inventario.
- Terminal de visual studio code.
- Ejecutar correctamente un script.
- Uso de la vista de Carga Masiva de inventario.
- Ejecución de los scripts.
- Script Cargue CEO.
- Script Cargue e instancia Splitters 1N – CEO.
- Script Cargue e instancia Puerto Splitter 1N – Splitter 1N.
- Script Cargue NAP.
- Script Cargue e instancia Splitters 2N – NAP.
- Script Cargue e instancia Puerto Splitter 2N – Splitter 2N.
- Script Cargue Cables
- Script Source – Target – Cable.
- Script Cargue e Instancia Hilos.
- Script Tramo a Tramo Hilos Distribución.
- Script Tramo a Tramo Hilos Troncales.
- Script Puerto Splitter 2N – Hilo.
- Script Puerto Splitter 1N – Hilo.
- Script Cargue ODF.
- Script Cargue e Instancia Bandeja ODF – ODF.
- Script Cargue e Instancia Puerto Bandeja ODF – Bandeja.
- Script Cargue e Instancia Tarjeta OLT.
- Script Cargue e Instancia Puerto Tarjeta OLT.
- Script Instancia UEN – Cable
- Script Instancia Puerto ODF – Hilo Troncal.
- Script Instancia UEN -NAP, UEN – CEO, UEN – HUB.
1.RECURSOS NECESARIOS
Los recursos que fueron utilizados para la obtención de la información de cargue fueron los siguientes.
- Archivo geoJson de los Tramos asociados a la red.

- Archivo geoJson de las CEO asociadas a la red.

- Archivo geoJson de las NAP asociadas a la red.
- Archivo geoJson de la OLT – HUB relacionada con la red

- Archivo Excel general de la información de la red
2. VISTAS UTILIZADAS PARA EL CARGUE DE LOS ARCHIVOS
Para el cargue de los elementos se utilizaron dos vistas: EXPLORADOR DE ENTIDADES y CARGA MASIVA DE INVENTARIO.
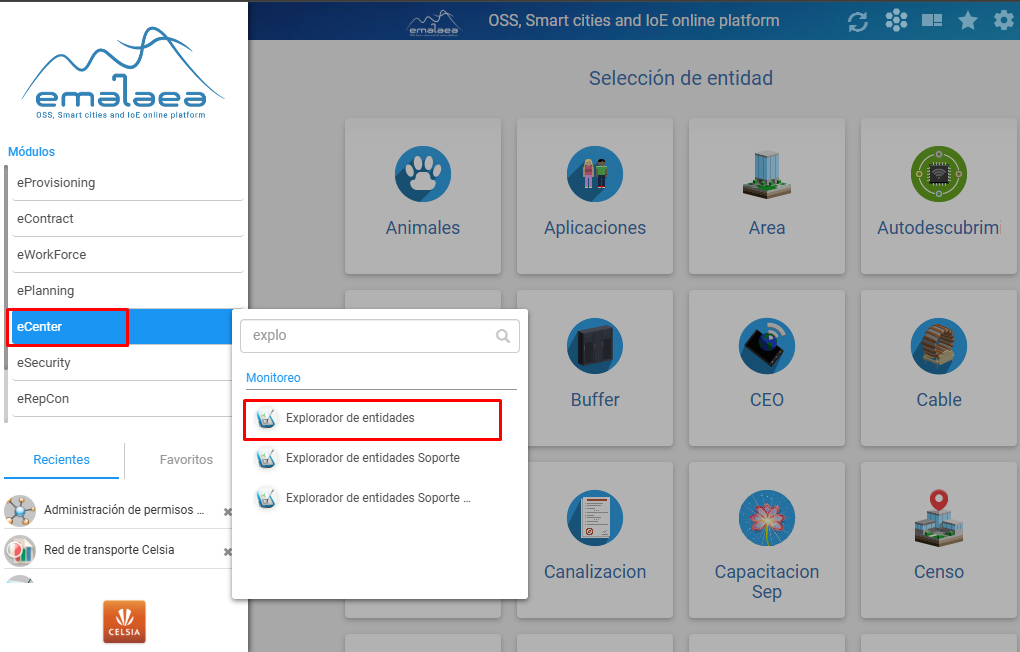
- EXPLORADOR DE ENTIDADES:
Se encuentra en el módulo de eCenter nos ayudará para el cargue de elementos
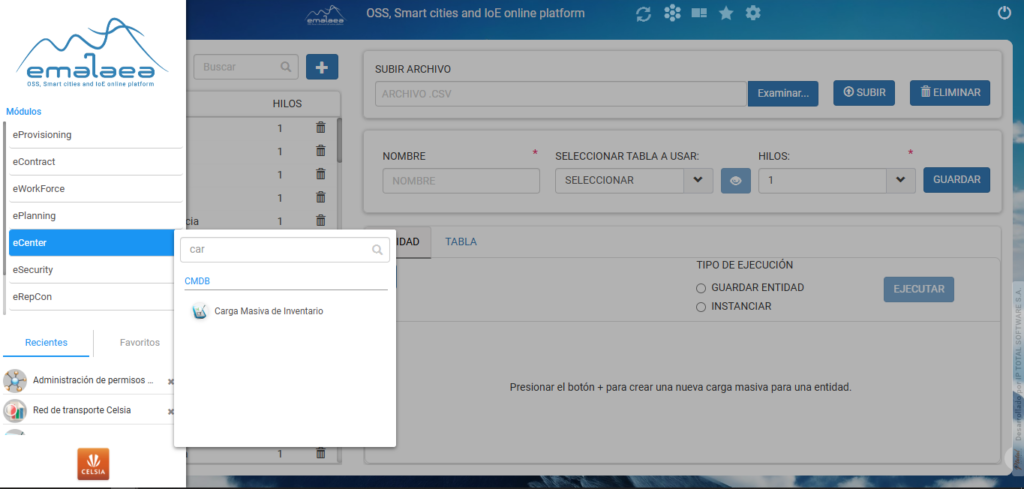
- CARGA MASIVA DE INVENTARIO:
Se encuentra en el módulo de eCenter y nos ayudará con el cargue y también con la instancia
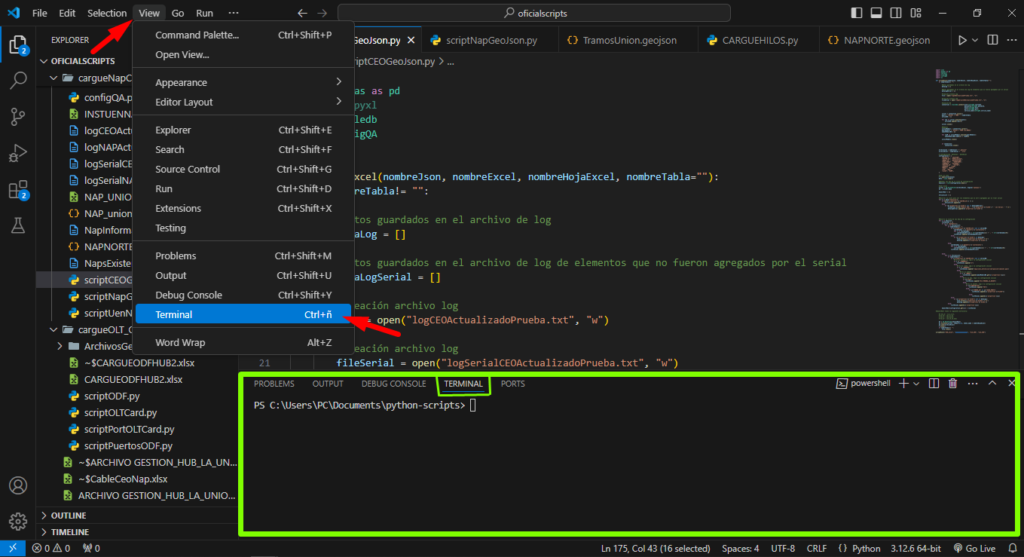
3. ABRIR TERMINAL VS CODE
- Damos Clic derecho en nuestra carpeta de scriptsCargue y seleccionamos en abrir con Visual Studio Code
- Ve al menú superior y haz clic en “Ver” (View).
- Selecciona la opción “Terminal” en el menú desplegable y se abrirá la terminal.
- Con la combinación de teclas Ctrl + ñ también se puede acceder a la terminal.
3.1 EJECUTAR CORRECTAMENTE UN SCRIPT
Una vez abierta la terminal nos aseguraremos de estar en la ruta correcta, es decir la ruta donde se encuentra nuestro archivo script. Si mantenemos el cursor sobre el nombre del archivo, nos mostrará la ruta en la cual se encuentra.
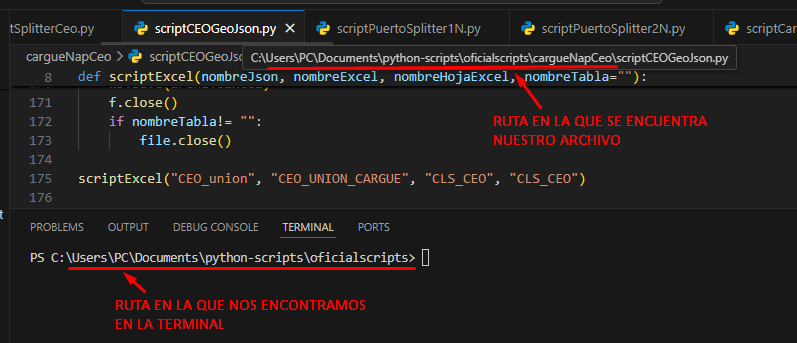
En este caso tenemos que la ruta de la terminal no coincide con la del archivo, veamos como navegar por las rutas:
Si no estás en la ruta donde está tu archivo, usa el comando “cd” para navegar hasta la carpeta donde se encuentra tu archivo en este caso debemos ingresar a la carpeta cargueNapCeo porque es ahí donde está el script que vamos a ejecutar, entonces utilizamos el comando “cd cargueNapCeo”.
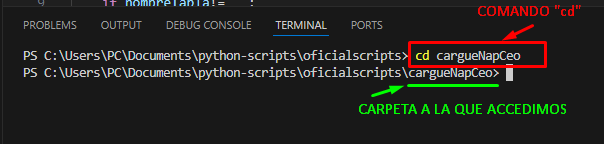
En caso de que tengas que retroceder entre carpetas en tu ruta el comando sería “cd ..” es decir “cd” seguido de dos puntos, esto nos permitirá ir una carpeta atrás en la ruta.
Una vez validemos que estamos en la ruta correcta ejecutaremos el script escribiendo en la consola el comando “py” seguido del nombre de nuestro archivo:
“py Nombre_de_archivo.py” y ejecutamos con Enter.

Después de ejecutar el script, en caso de algún error en la generación del archivo, se mostrará en la misma terminal el motivo por el cual falló, la terminal nos informará, el tipo de error y la línea donde ocurrió. En caso de que no haya errores, el script se ejecutará correctamente y se generará un Excel con la información del elemento.
4. CÓMO USAR LA VISTA CARGA MASIVA DE INVENTARIO
Para ejecutar un cargue desde la vista de carga masiva es importante tener en cuenta que al momento de subir el archivo con la información que queremos cargar e instanciar, este debe estar en formato “.csv” es decir que si el archivo generado es “.xlsx” deberás convertirlo en un archivo “.csv”
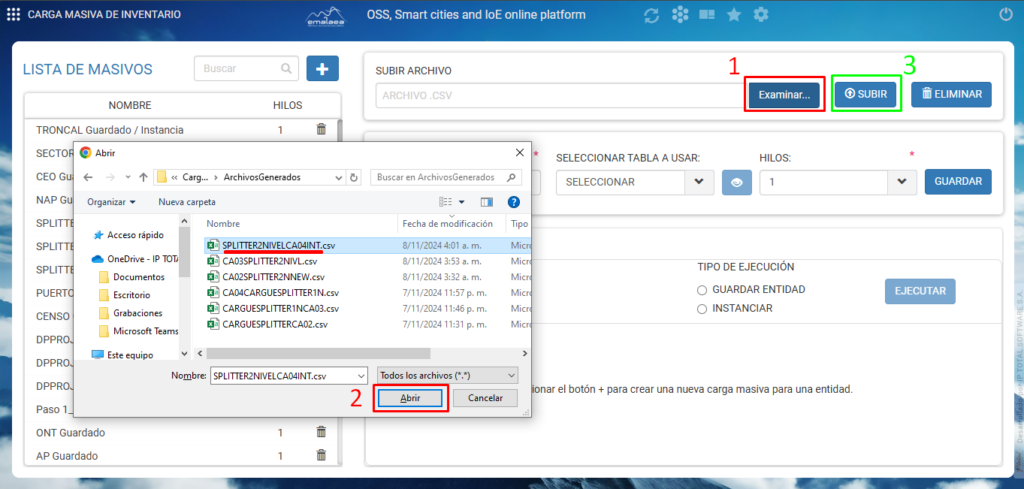
- Una vez en la vista seleccionaremos el botón examinar para seleccionar el archivo que deseamos subir.
- Seleccionamos el archivo con la información de cargue o instancia.
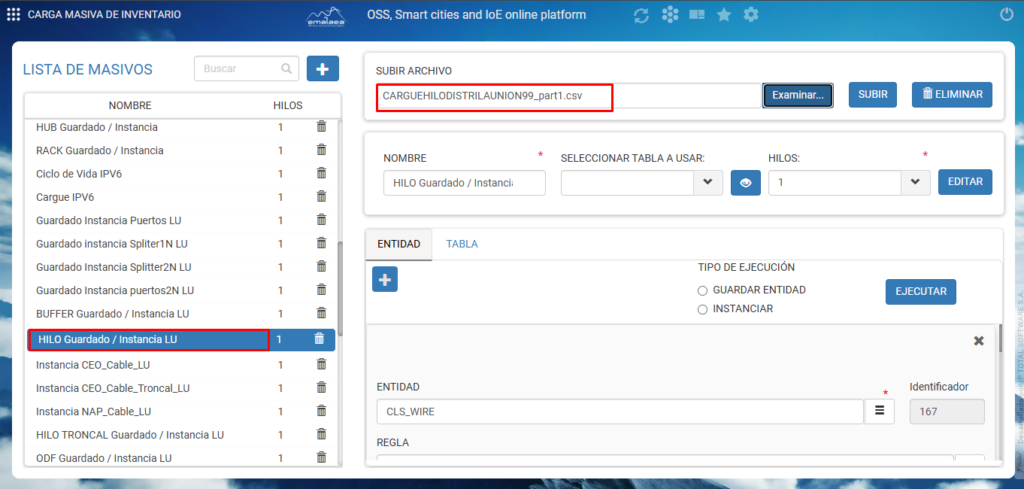
- Una vez cargado a la vista, seleccionamos SUBIR para cargar los elementos en una tabla temporal, esto para llevar un registro sobre los elementos que se están cargando y en caso de que no se pueda cargar, podamos identificarlo
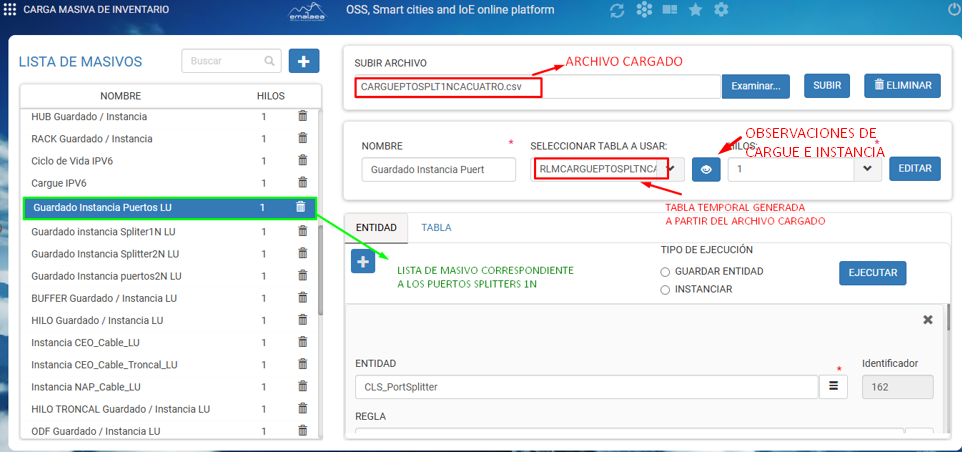
En esta imagen se puede observar el archivo cargado, la lista de masivo, la tabla seleccionada (que se generó en base a el archivo que cargamos), observaciones de cargue e instancia.
Una vez el archivo esté cargado en la vista, debemos seleccionar la hoja de carga masiva correspondiente a los elementos e información que contiene el archivo cargado, también veremos el nombre del archivo cargado y el nombre de la tabla temporal creada para cargar los archivos
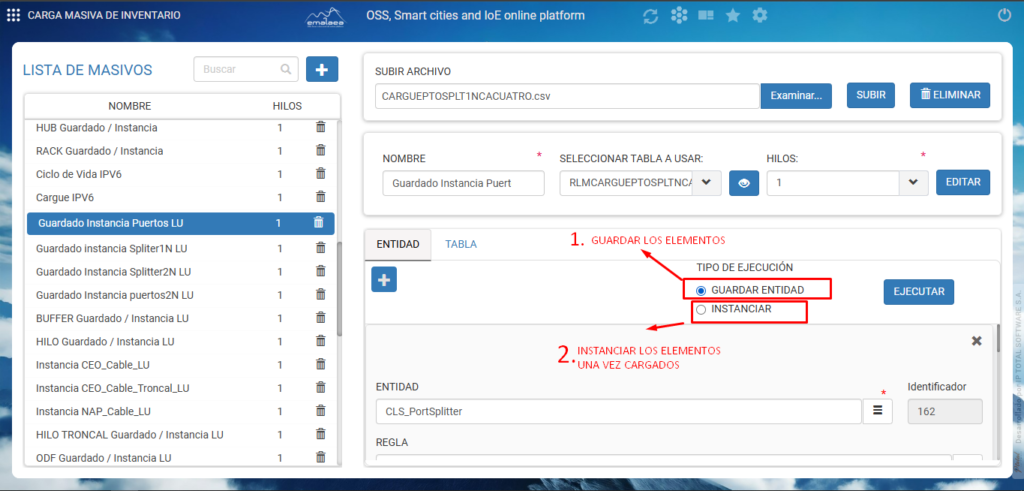
En los archivos cuya lista masiva tenga en su nombre “Guardado / instancia” seleccionaremos primero la opción de “Guardar entidad” y ejecutaremos, una vez ejecutado el cargue revisamos las observaciones que nos brinda las vista donde podemos confirmar si los elementos se cargaron correctamente o se presentó algún error de cargue esto en la siguiente imagen.
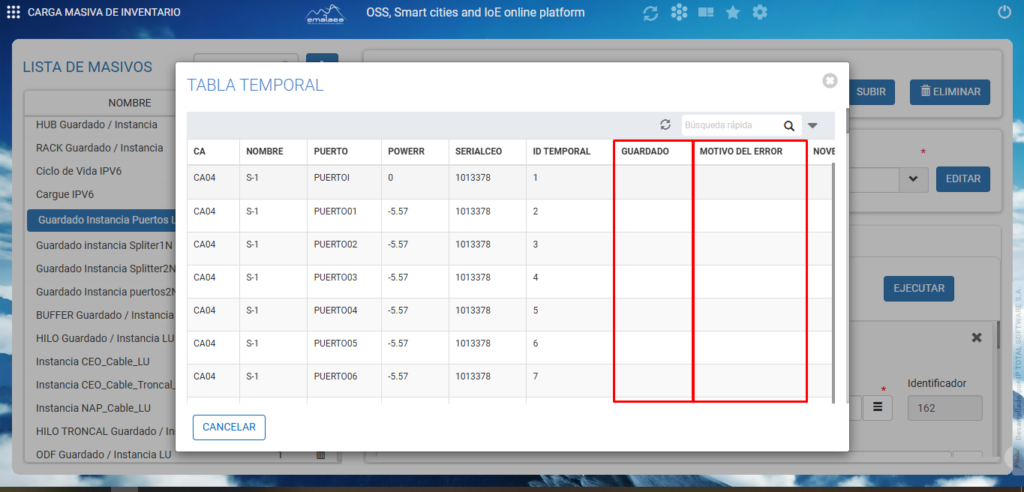
En observaciones de cargue e instancia tendremos esta tabla que nos presenta estas dos columnas Guardado y Motivo del error. Una vez se realice el cargue o instancia del archivo que seleccionamos se actualizarán estas columnas y nos informarán si hubo errores de cargue o si se cargó correctamente,
Una vez confirmemos que se cargaron los elementos, vamos a seleccionar en esa misma hoja de masivo y con el mismo archivo la opción de Instanciar y ejecutamos. Revisaremos las observaciones para confirmar que se realizó correctamente la instancia de los elementos o si se presentaron errores en la instancia.
5.EJECUCIÓN DE LOS SCRIPTS.
5.1 SCRIPT CARGUE CEO:
Abrimos nuestro archivo scriptCEOGeoJson.py con Visual Studio y nos aseguramos de que los siguientes parámetros estén correctos:
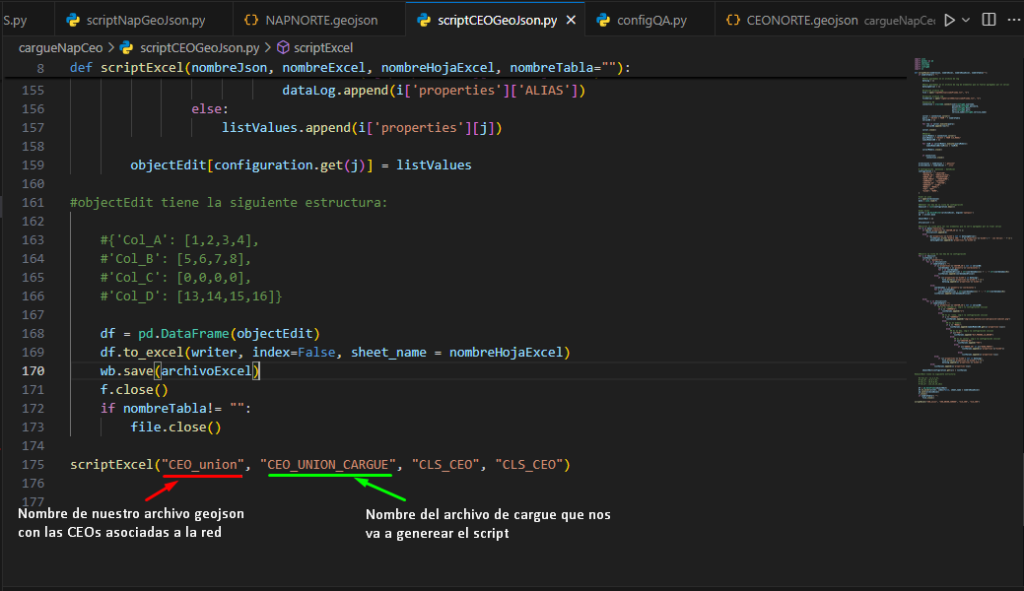
- Nombre geoJson CEO: geoJson con la información de las CEO’s vinculadas a la red.
- Nombre del Archivo de cargue: Será el nombre que tendrán los archivos generados por el script.
Una vez comprobemos nuestros parámetros, ejecutaremos el script en la terminal de VS Code utilizando el comando “py scriptCEOGeoJson.py” y asegurandonos de estar en la ruta correcta (Ver pag 4 – pag 5)

Una vez ejecutado el script se nos generará un archivo Excel con la información de las CEO’s:
Se verá de esta manera:
Carga masiva de objetos: una vez generado el archivo de cargue, Ingresaremos a la vista EXPLORADOR DE ENTIDADES seleccionaremos el elemento CEO >> VER TODAS y le daremos en el botón carga masiva de objetos y en la opción de examinar subiremos nuestro archivo.
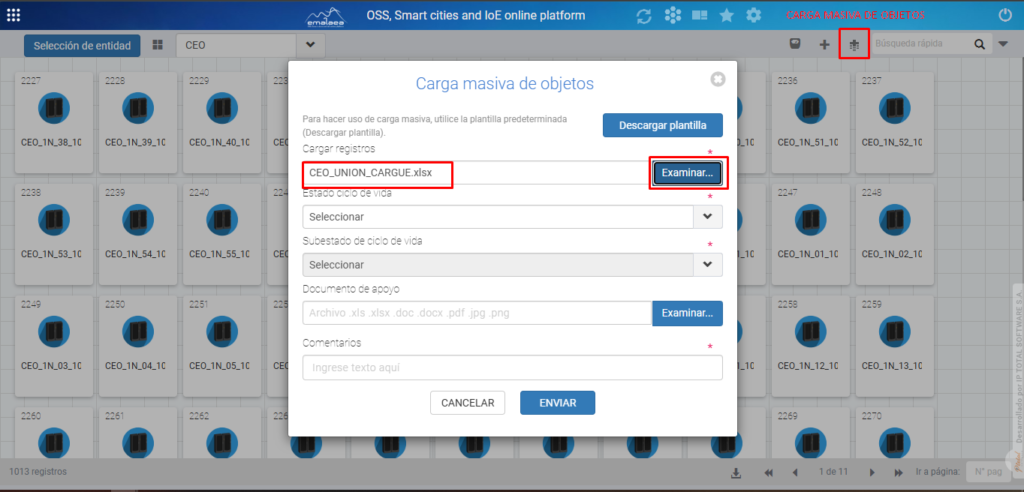
Una vez llenemos los campos necesarios se selecciona enviar y se nos cargarán los elementos.
5.1.1 SCRIPT CARGUE E INSTANCIA SPLITTERS (1N) CEO
Para el cargue de los Splitter 1N Abrimos nuestro archivo scriptSplitterCeo.py con Visual Studio y debemos tener en cuenta los siguientes parámetros:
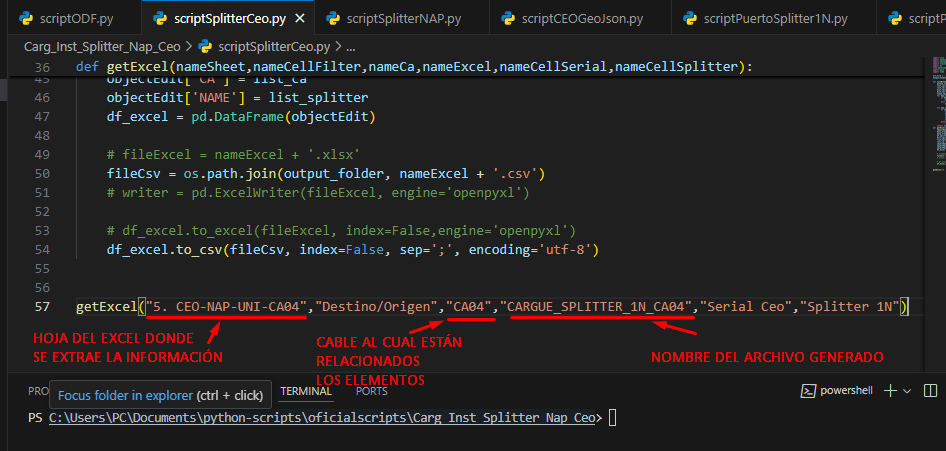
- HOJA DEL EXCEL DONDE SE EXTRAE LA INFORMACIÓN: El Excel general contiene varias hojas con información de los cables y sus elementos asociados. Actualmente se está extrayendo información del cable 04 desde la hoja “5. CEO-NAP-UNI-CA04”. Para trabajar con otros cables, será necesario cambiar el nombre de la hoja al correspondiente.
- CABLE AL CUAL ESTAN RELACIONADOS LOS ELEMENTOS: Debido a que la hoja de la cual estamos extrayendo la información es a la del CABLE 04 este parámetro deberá ser CA04, cuando estemos extrayendo la información de la hoja del CABLE 03 este parámetro deberá ser CA03 y de esta misma manera con los demás cables.
- NOMBRE DEL ARCHIVO GENERADO: Este parámetro deberá ser modificado por cada ejecución en los 3 diferentes cables ya que no se puede generar más de un archivo con el mismo nombre, es decir cuando se esté apuntando al CABLE 04 el nombre del archivo deberá hacer referencia a este CABLE 04 y si se apunta al CABLE 02 el nombre del archivo deberá hacer referencia a este último.
Una vez verifiquemos que nuestros parámetros estén correctos, podremos ejecutar nuestro archivo desde la terminal de VS Code (ver, Pag 4 – Pag 5).
El archivo generado por este script lo subiremos a la vista de CARGA MASIVA DE INVENTARIO en donde seleccionaremos la hoja de cargue llamada “Guardado instancia Spliter1N LU” y ejecutaremos el guardado e instancia (Ver, Pag 6 – Pag 7).
5.1.2 SCRIPT PUERTO SPLITTER (1N) – SPLITTERS 1N
Abrimos nuestro archivo scriptPuertoSplitter1N.py con Visual Studio validaremos los siguientes parámetros:
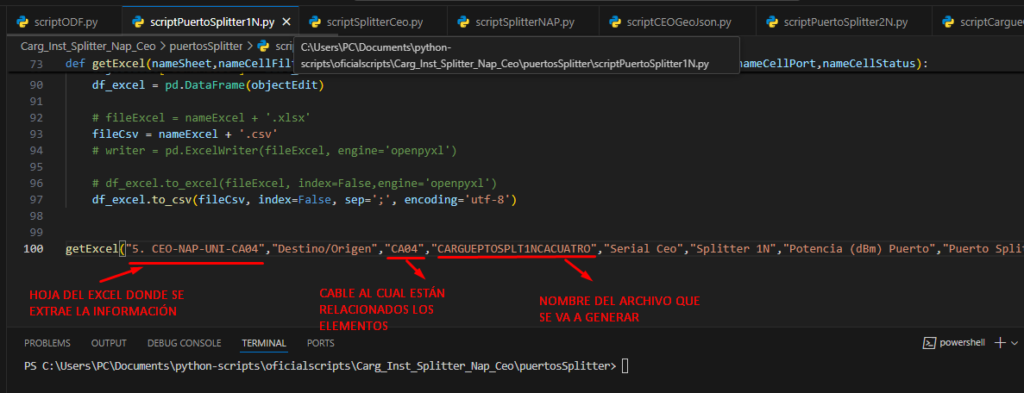
Estos parámetros se manejan de la misma manera que los parámetros del script Splitter CEO (1N) (ver Pag 10) una vez tengamos los parámetros correctos se ejecuta el script.
Ejecutamos nuestro archivo scriptPuertoSplitter1N.py desde la terminal de VS Code asegurándonos de estar en la ruta correcta (ver Pag 4- Pag 5) con el comando “py scriptPuertoSplitter1N.py”
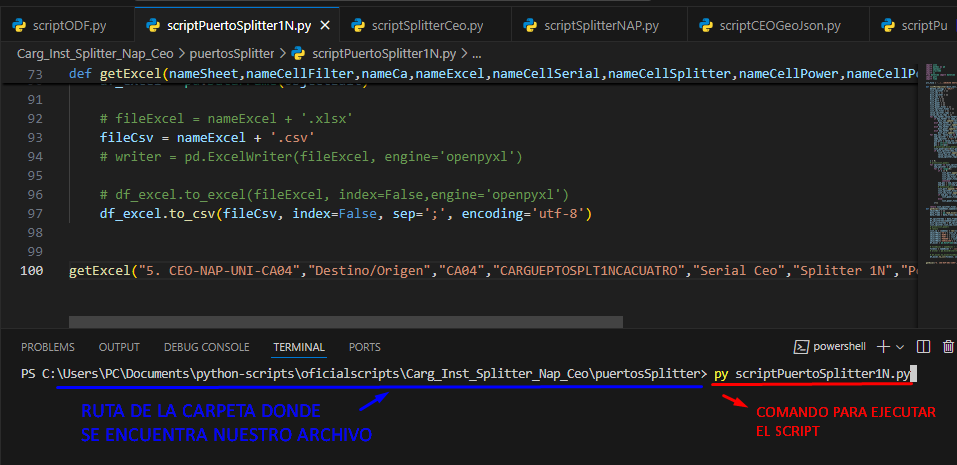
El archivo generado por este script lo subiremos a la vista de CARGA MASIVA DE INVENTARIO en donde seleccionaremos la hoja de carga llamada “Guardado Instancia Puertos LU” y ejecutaremos el guardado e instancia del archivo (Ver, Pag 6 – Pag 7).
5.2 SCRIPT CARGUE NAP:
Abrimos nuestro archivo scriptNapGeoJson.py con Visual Studio verificamos los siguientes parámetros:
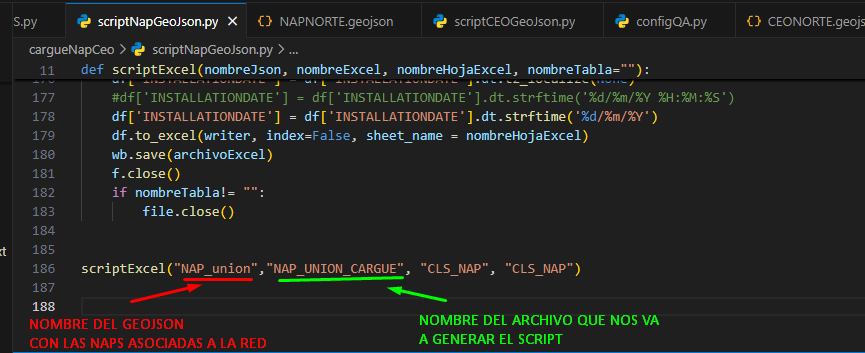
- Nombre geoJson NAP: geoJson con la información de las NAP’s vinculadas a la red.
- Nombre del Archivo de cargue: Será el nombre que tendrá el archivo generado por el script.
Ejecutamos nuestro archivo scriptNapGeoJson.py desde la terminal de VS Code asegurándonos de estar en la ruta correcta (ver Pag 4- Pag 5)

Una vez se genere el archivo de cargue NAP, Ingresaremos a la vista EXPLORADOR DE ENTIDADES, seleccionaremos el elemento NAP>> VER TODAS y le daremos en el botón carga masiva de objetos y en la opción de examinar subiremos nuestro archivo que se generó en el paso anterior.
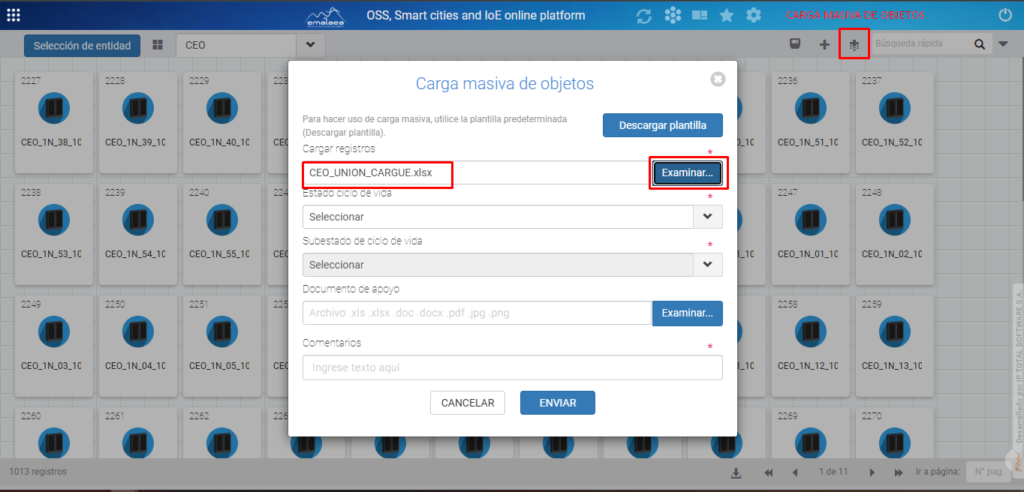
Una vez llenemos los campos necesarios, se envía la información y de esta manera se nos cargarán los elementos.
5.2.1 SCRIPT CARGUE E INSTANCIA SPLITTERS 2N – NAP
Abrimos nuestro archivo scriptSplitterNAP.py con Visual Studio modificaremos los siguientes parámetros:

- HOJA DEL EXCEL DONDE SE EXTRAE LA INFORMACIÓN: El Excel general contiene varias hojas con información de los cables y sus elementos asociados. Actualmente se está extrayendo información del cable 04 desde la hoja “5. CEO-NAP-UNI-CA04”. Para trabajar con otros cables, será necesario cambiar el nombre de la hoja al correspondiente.
- CABLE AL CUAL ESTAN RELACIONADOS LOS ELEMENTOS: Debido a que la hoja de la cual estamos extrayendo la información es a la del CABLE 04 este parámetro deberá ser CA04, cuando estemos extrayendo la información de la hoja del CABLE 03 este parámetro deberá ser CA03 y de esta misma manera con los demás cables.
- NOMBRE DEL ARCHIVO GENERADO: Este parámetro deberá ser modificado por cada ejecución en los 3 diferentes cables ya que no puedes generar dos archivos con el mismo nombre, es decir cuando se esté apuntando al CABLE 04 el nombre del archivo deberá hacer referencia a este CABLE 04 y si se apunta al CABLE 02 el nombre del archivo deberá hacer referencia a este último.
Una vez verifiquemos que nuestros parámetros estén correctos, podremos ejecutar nuestro archivo desde la terminal de VS Code asegurándonos de estar en la ruta correcta (ver, Pag 4 – Pag 5) con el comando “py scriptSplitterNAP.py”
El archivo generado por este script lo subiremos a la vista de CARGA MASIVA DE INVENTARIO en donde seleccionaremos la hoja de carga llamada “Guardado Instancia Splitter2N LU” y ejecutaremos el guardado e instancia (Ver, Pag 6 – Pag 7).
- SCRIPT PUERTO SPLITTER 2N – SPLITTER (2N)
Abrimos nuestro archivo scriptPuertoSplitter2N.py con Visual Studio y verificamos los siguientes parámetros:
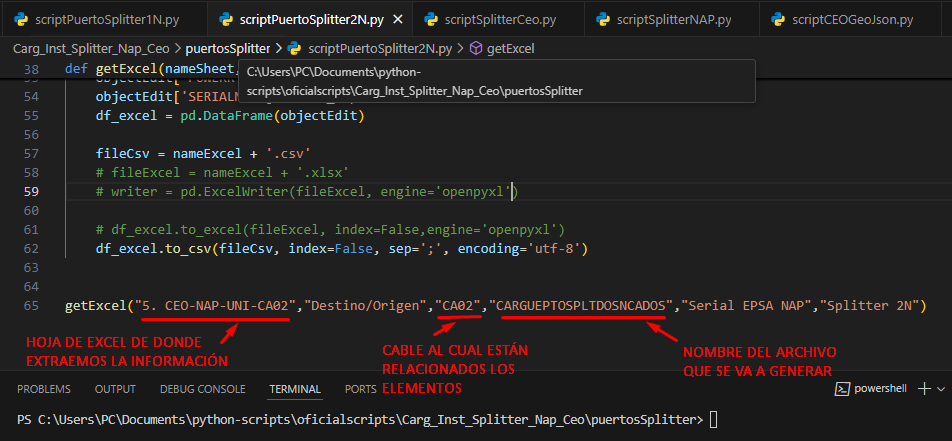
Estos parámetros se manejan de la misma manera que los parámetros del script del SPLITTER NAP (2N) (Pag 13 – Pag 14) una vez tengamos los parámetros correctos se ejecuta el script.
Ejecutamos nuestro archivo scriptPuertoSplitter1N.py desde la terminal de VS Code asegurándonos de estar en la ruta correcta (ver Pag 4- Pag 5)
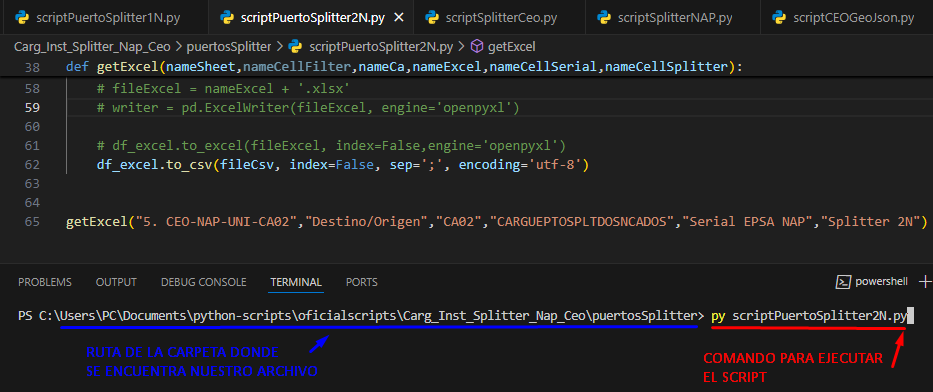
El archivo generado por este script lo subiremos a la vista de CARGA MASIVA DE INVENTARIO en donde seleccionaremos la hoja de carga llamada “Guardado instancia Spliter2N LU” y ejecutaremos el guardado e instancia del archivo (Ver, Pag 6 – Pag 7).
5.3 SCRIPT CARGUE CABLES
scriptCargueCables_la_union.py
Abrimos nuestro archivo scriptCargueCables_la_union.py con Visual Studio verificamos los siguientes parámetros:
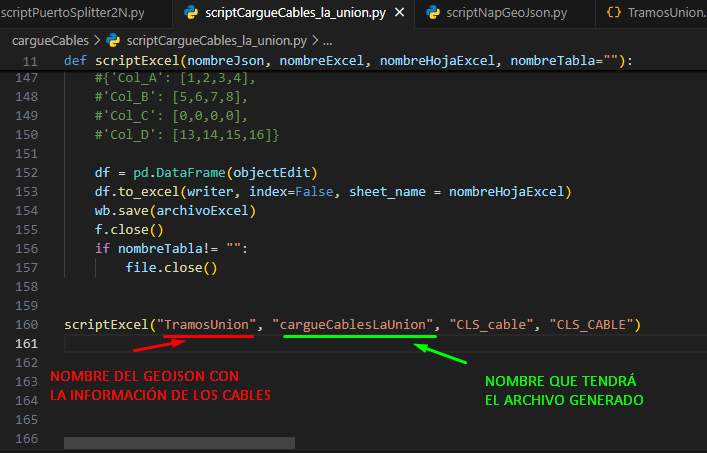
- Nombre geoJson Tramos: geoJson con la información de los Tramos asociados a la red.
- Nombre del Archivo de cargue: Será el nombre que tendrá el archivo generado por el script.
Lo siguiente que debemos hacer es abrir la terminal de VS Code y asegurarnos de que la ruta esté apuntando a la carpeta donde está nuestro archivo (ver, Pag 4 – Pag 5) una vez estamos en la ruta correcta ejecutamos el archivo con el comando:
“py scriptCargueCables_la_union.py”
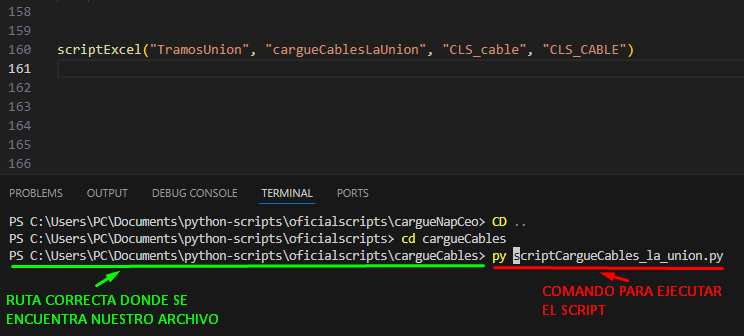
Una vez generado el archivo Excel correctamente, ingresaremos a la vista EXPLORADOR DE ENTIDADES seleccionaremos el elemento CABLE>> VER TODAS y le daremos en el botón carga masiva de objetos (ver imagen pag 9) y en la opción de examinar subiremos nuestro archivo que se generó en el paso anterior, completaremos los campos necesarios y enviaremos nuestra información a cargar
5.4 SCRIPT SOURCE TARGET CABLE
Este script se utilizará para generar un archivo que detalle los cables y los elementos con los que están conectados. Su propósito es organizar la información de forma estructurada, sirviendo como base para los próximos scripts que se desarrollarán.
Abriremos nuestro archivo scriptSourceTargetCABLE.py y comprobamos que nuestros parámetros estén correctos.

- Nombre geoJson Tramos: geoJson con la información de las tramos vinculados a la red.
- Nombre del Archivo de cargue: Este nombre debe ser “CableCeoNap” generado por el script.
- Serial de la HUB: Este serial lo sacamos del geoJson de la hub que se nos compartió en los recursos.
Lo siguiente que debemos hacer es a través de la terminal de VS Code asegurándonos que la ruta esté apuntando a la carpeta donde está nuestro archivo ejecutamos el archivo con el comando: “py scriptSourceTargetCABLE.py” (ver, Pag 4 – Pag 5).
Una vez generado el archivo CableCeoNap este no se cargará ni instanciará, este archivo se utilizará para los siguientes scripts.
5.5 SCRIPT CARGUE E INSTANCIA HILOS
Abriremos Nuestro script CARGUEHILOS.py y comprobaremos que los siguientes parámetors estén correctos:
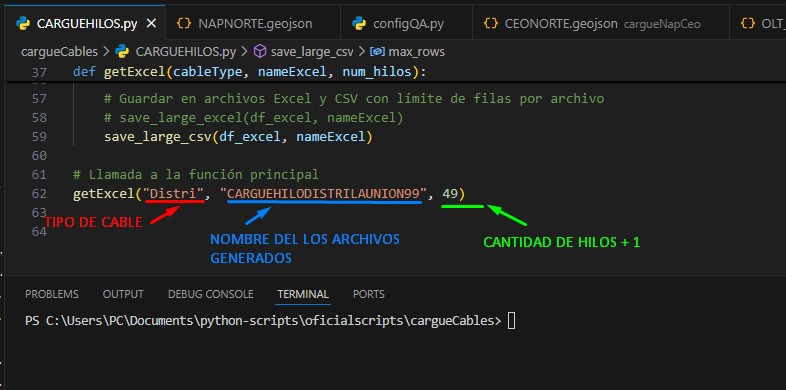
- TIPO DE CABLE: Este parametros nos ayudara a diferenciar a que tipo de cable le vamos a generar los hilos, en la imagen podemos ver “Distri” y lo que haremos es generar los hilos de los cables de tipo Distribución. Una vez generado los hilos de distribución, este parametro se debe remplazar por “Tronc” para generar los hilos de los cables de tipo Troncal.
- NOMBRE DE LOS ARCHIVOS GENERADOS: Será el nombre que tendrán los archivos generados por el script.
- CANTIDAD DE HILOS +1: Este parametro nos indica la cantidad de hilos que se van a generar por cada cable + 1, es decir la cantidad de hilos para un cable de Distribución es de 48 hilos el parámetro será 48+1= 49 En el caso de los cables troncales son 144 hilos es decir 144+1 =145 el parámetro debera ser remplazado por 145 en caso de los troncales
Una vez comprobemos nuestros parámetros ejecutaremos el script en la terminal de VS Code utilizando el comando “py CARGUEHILOS.py” y asegurandonos de estar en la ruta correcta (Ver pag 4 – pag 5)
Es importante tener en cuenta que este script nos generará un archivo por cada 4800 hilos (100 Cables de distribución) y se clasifican por “partes” en caso de que hayan mas de 4800 hilos se generará un segundo archivo clasificado “part2” y así cada 4800 hilos de esta manera tendremos un mejor orden en el cargue e instancia de estos hilos.
Carga masiva: Una vez generados los archivos con la información de los Hilos iremos a la vista de CARGA MASIVA en dondeseleccionaremos la lista “HILO Guardado / Instancia LU” realizaremos el cargue de los hilos y la instancia con sus cables (Ver, Pag 6 – Pag 7)
5.5.1 SCRIPT TRAMO A TRAMO DISTRIBUCIÓN
Abriremos Nuestro script scriptInsHiloHilo.py y comprobaremos que los siguientes parámetors estén correctos:
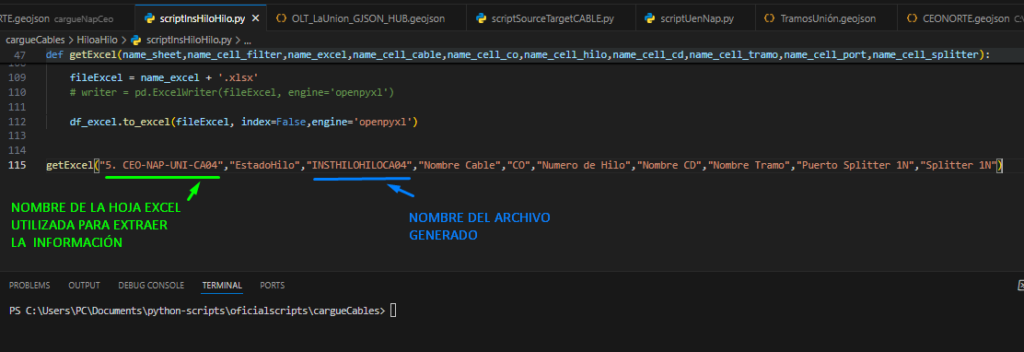
- NOMBRE DE LA HOJA EXCEL: Este parámetro tendrá que ser remplazado por cada una de las hojas de los CABLES por las que viene segmentado el Excel con la informcion general de la red debemos ejecutarlo una vez por cada hoja.
- NOMBRE DEL ARCHIVO GENERADO: El nombre con el cual se generará el archivo, debe ser remplazado por cada hoja.
Ejecutar script: Una vez comprobado que los parametros estén correctos ejecutaremos el script desde la terminal de VS Code con el comando “py scriptInsHiloHilo.py” asegurándonos de estar en la ruta correcta.
Carga masiva: Una vez generados los archivos con la información de los Hilos iremos a la vista de CARGA MASIVA en donde seleccionaremos la lista “Instancia Hilo / Hilo LU” realizaremos solo la instancia de la información ya que los hilos se encuentran cargados (Ver, Pag 6 – Pag 7)
Importante: con esta instance realizaremos la instancia Hilo a Hilo es decir la union de los hilos por tramo es decir “Hilo 01 del tramo 1 relacionado con Hilo 01 del tramo 2 ”.
5.5.2 SCRIPT TRAMO A TRAMO TRONCAL
Abriremos Nuestro script scriptInsHiloHiloTroncal.py y comprobaremos que los siguientes parámetors estén correctos:
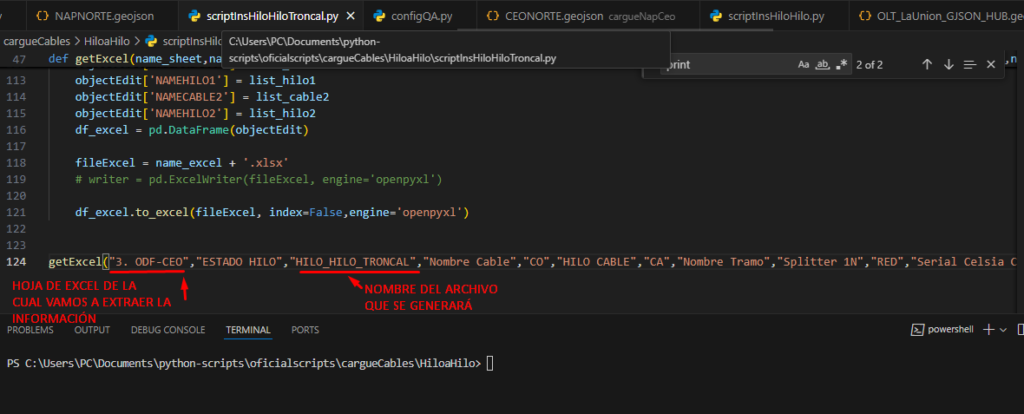
- NOMBRE DE LA HOJA EXCEL: Es la hoja en la cual se encuentra la información de los cables troncales.
- NOMBRE DEL ARCHIVO GENERADO: El nombre con el cual se generará el archivo, debe ser remplazado por cada hoja.
Ejecutar script: Una vez comprobado que los parametros estén correctos ejecutaremos el script desde la terminal de VS Code con el comando “py scriptInsHiloHiloTroncal .py” asegurándonos de estar en la ruta correcta.
Carga masiva: Una vez generados los archivos con la información de los Hilos iremos a la vista de CARGA MASIVA en donde seleccionaremos la lista “Instancia Hilo / Hilo LU” realizaremos solo la instancia de la información ya que los hilos se encuentran cargados (Ver, Pag 6 – Pag 7)
Importante: con esta instance realizaremos la instancia Hilo a Hilo es decir la union de los hilos por tramo es decir “Hilo 01 del tramo 1 relacionado con Hilo 01 del tramo 2 ”.
5.6 SCRIPT PUERTO SPLITTER 2N – HILO
Abriremos Nuestro script scriptInsSplt2NHilo.py y comprobaremos que los siguientes parámetors estén correctos:
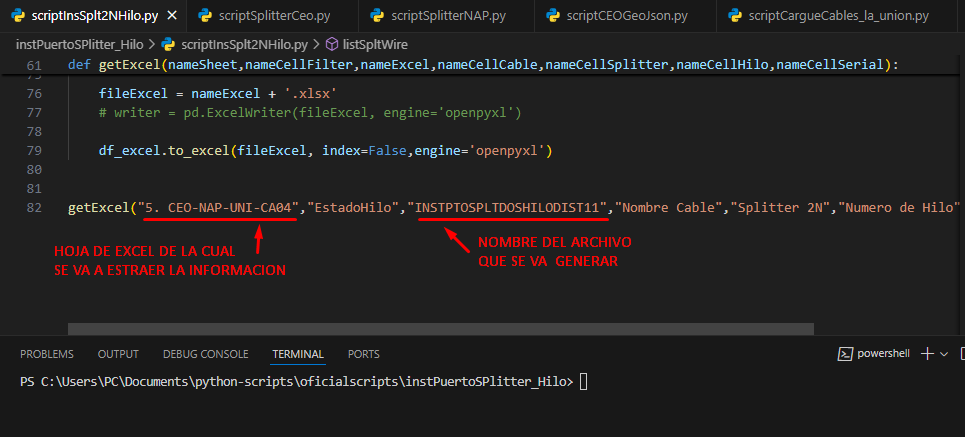
- NOMBRE DE LA HOJA EXCEL: Es la hoja} del archivo general de la cual vamos a extraer la información que necesitamos, se divide por CABLES y deberemos ejecutar una vez el script por cada hoja de cable.
- NOMBRE DEL ARCHIVO GENERADO: El nombre con el cual se generará el archivo para realizar el cargue o instancia. Debe ser remplazado por cada hoja.
Ejecutar script: Una vez comprobado que los parametros estén correctos ejecutaremos el script desde la terminal de VS Code con el comando “py scriptInsSplt2NHilo.py” asegurándonos de estar en la ruta correcta (ver Pag 4 – Pag 5).
Carga masiva: Una vez generados los archivos con la información de los Hilos y ´puertos iremos a la vista de CARGA MASIVA en donde seleccionaremos la lista “Splitter 2n / Hilo LU” realizaremos solo la instancia de la información ya que los splitters y los hilos se encuentran cargados (Ver, Pag 6 – Pag 7)
5.6.1 SCRIPT PUERTO SPLITTER 1N – HILO TRONCAL
Abriremos Nuestro script scriptInsSpltHiloTroncalOf.py y comprobaremos que los siguientes parámetros estén correctos:
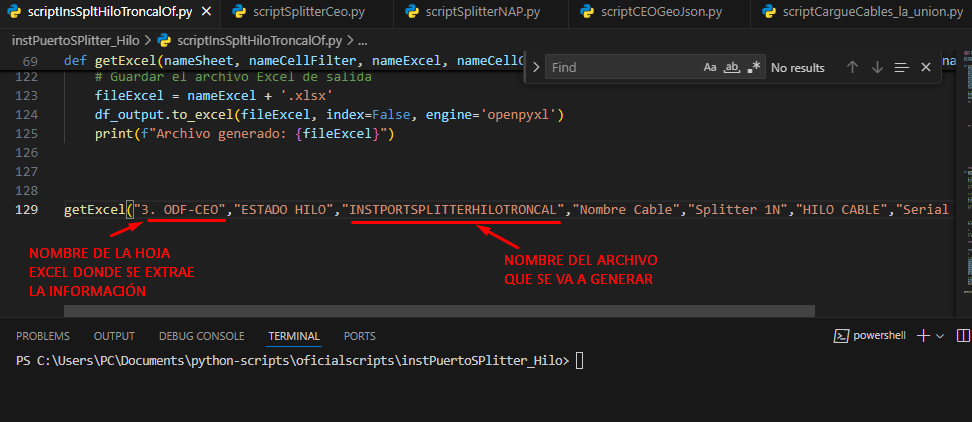
- NOMBRE DE LA HOJA EXCEL: Es la hoja del archivo general de la cual vamos a extraer la información que necesitamos en este caso es la hoja “3. ODF-CEO” que tiene la información de los cables troncales.
- NOMBRE DEL ARCHIVO GENERADO: El nombre con el cual se generará el archivo para realizar el cargue o instancia.
Ejecutar script: Una vez comprobado que los parametros estén correctos ejecutaremos el script desde la terminal de VS Code con el comando “py scriptInsSpltHiloTroncalOf.py” asegurándonos de estar en la ruta correcta (ver Pag 4 – Pag 5).
Carga masiva: Una vez generados los archivos con la información de los Hilos y Puertos iremos a la vista de CARGA MASIVA en donde seleccionaremos la lista “Instancia Puerto Splitter / Hilo Troncal LU” realizaremos solo la instancia de la información ya que los splitters y los hilos se encuentran cargados (Ver, Pag 6 – Pag 7)
5.7 SCRIPT CARGUE ODF
Abrimos nuestro archivo scriptODF.py con Visual Studio y nos aseguramos de que los siguientes parámetros estén correctos:
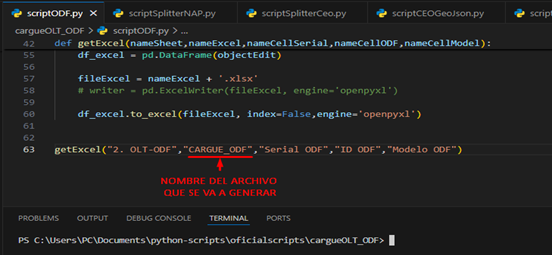
- NOMBRE DE ARCHIVO GENERADO: es el nombre que va a tener el archivo de cargue.
Ejecutar script: Una vez comprobado que los parametros estén correctos ejecutaremos el script desde la terminal de VS Code con el comando “py scriptODF.py” asegurándonos de estar en la ruta correcta (Ver Pag 4 – Pag 5)
Carga masiva: Una vez generados los archivos con la información de los ODF iremos a la vista de CARGA MASIVA en donde seleccionaremos la lista “ODF Guardado La Unión” realizaremos solo la instancia de la información ya que los hilos se encuentran cargados (Ver, Pag 6 – Pag 7)
5.7.1 SCRIPT CARGUE E INSTANCIA BANDEJAS ODF – ODF.
Abrimos nuestro archivo scriptBandejaODF.py con Visual Studio y nos aseguramos de que los siguientes parámetros estén correctos:
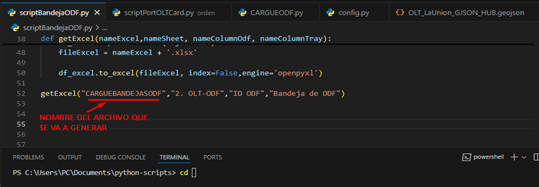
- Nombre de archivo generado: es el nombre que va a tener el archivo de cargue
Ejecutar script: Una vez comprobado que los parametros estén correctos ejecutaremos el script desde la terminal de VS Code con el comando “py scriptBandejaODF.py” asegurándonos de estar en la ruta correcta (Ver Pag 4 – Pag 5)
Carga masiva: Una vez generados los archivos con la información de las bandejas ODF iremos a la vista de CARGA MASIVA en donde seleccionaremos la lista “Bandeja ODF Guardado / Instancia” realizaremos solo la instancia de la información ya que los hilos se encuentran cargados (Ver, Pag 6 – Pag 7)
5.7.2 SCRIPT CARGE E INSTANCIA PUERTOS BANDEJAS ODF
Abrimos nuestro archivo scriptPuertosODF.py con Visual Studio y nos aseguramos de que los siguientes parámetros estén correctos:
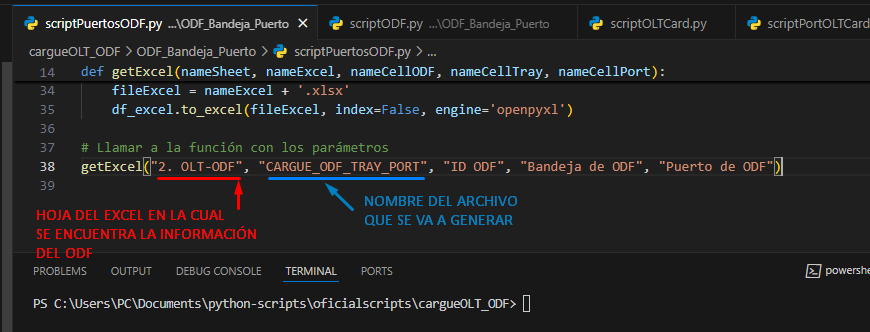
- HOJA DE EXCEL CON LA INFORMACIÓN : Es la hoja en la cual se encuentra la información del ODF.
- NOMBRE DE ARCHIVO GENERADO: es el nombre que va a tener el archivo de cargue
Ejecutar script: Una vez comprobado que los parametros estén correctos ejecutaremos el script desde la terminal de VS Code con el comando “py scriptPuertosODF.py” asegurándonos de estar en la ruta correcta (Ver Pag 4 – Pag 5)
Carga masiva: Una vez generados los archivos con la información de los puertos bandeja ODF iremos a la vista de CARGA MASIVA en donde seleccionaremos la lista “Puerto ODF TRAY Guardado/Instancia LU” realizaremos el guardado y la instancia de la información (Ver, Pag 6 – Pag 7)
5.8 SCRIPT TARJETA OLT
Abrimos nuestro archivo scriptOLTCard.py con Visual Studio y nos aseguramos de que los siguientes parámetros estén correctos:

- HOJA DE EXCEL CON LA INFORMACIÓN:: Es la hoja en la cual se encuentra la información de la OLT.
- NOMBRE DE ARCHIVO GENERADO: es el nombre que va a tener el archivo de cargue
Ejecutar script: Una vez comprobado que los parametros estén correctos ejecutaremos el script desde la terminal de VS Code con el comando “py scriptOLTCard.py” asegurándonos de estar en la ruta correcta (Ver Pag 4 – Pag 5)
Carga masiva: Una vez generados los archivos con la información de las tarjetas OLT iremos a la vista de CARGA MASIVA en donde seleccionaremos la lista “OLT / Tarjetas de servicios Guardado / Instancia LU” realizaremos el guardado y la instancia de la información (Ver, Pag 6 – Pag 7)
5.8.1 SCRIPT PUERTO TARJETA OLT
Abrimos nuestro archivo scriptPortOLTCard.py con Visual Studio y nos aseguramos de que los siguientes parámetros estén correctos:
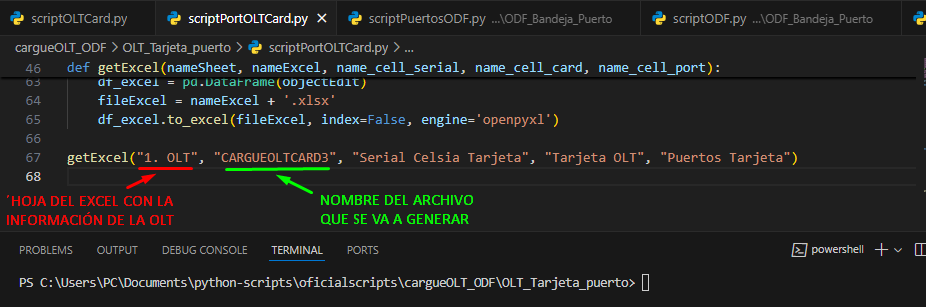
- HOJA DE EXCEL CON LA INFORMACIÓN: Es la hoja en la cual se encuentra la información de la OLT.
- NOMBRE DE ARCHIVO GENERADO: es el nombre que va a tener el archivo de cargue
Ejecutar script: Una vez comprobado que los parametros estén correctos ejecutaremos el script desde la terminal de VS Code con el comando “py scriptPortOLTCard.py” asegurándonos de estar en la ruta correcta (Ver Pag 4 – Pag 5)
Carga masiva: Una vez generados los archivos con la información de los puertos tarjeta OLT iremos a la vista de CARGA MASIVA en donde seleccionaremos la lista “Guardado Instancia Puerto / Tarjeta Olt LU” realizaremos el guardado y la instancia de la información (Ver, Pag 6 – Pag 7)
5.9 SCRIPT INSTANCIA UEN – CABLE
Abrimos nuestro archivo InstUENCable.py con Visual Studio y nos aseguramos de que los siguientes parámetros estén correctos:
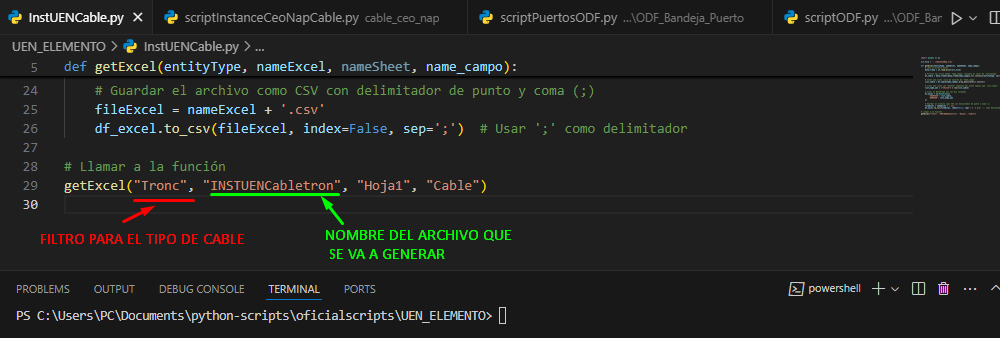
- FILTRO PARA TIPO DE CABLE: este parámetro nos filtra el tipo de cable con el cual se va a realizar la instancia con la UEN, es decir si lo definimos como “Tronc” el archivo se generará entre la UEN y los cables Troncales, si lo definimos como “Distri” me realizará el archivo entre la UEN y los cables de Distribución.
- NOMBRE DE ARCHIVO GENERADO: es el nombre que va a tener el archivo generado por el script
Ejecutar script: Una vez comprobado que los parametros estén correctos ejecutaremos el script desde la terminal de VS Code con el comando “py InstUENCable.py” asegurándonos de estar en la ruta correcta (Ver Pag 4 – Pag 5)
Carga masiva: Una vez generados los archivos con la información de los Cables y la UEN iremos a la vista de CARGA MASIVA en donde ependiendo de el tipo de cable con el que hayamos generado el archivo seleccionaremos la hoja de carga masiva, es decir si el filtro tipo de cable es “Tronc” entonces seleccionamos “Instancia UEN_Cable Troncal LU” si es “Distri”seleccionamos “Instancia UEN/Cable Distribucion LU” y realizaremos la instancia de la información (Ver, Pag 6 – Pag 7)
- SCRIPT PUERTO ODF – HILO TRONCAL
Abrimos nuestro archivo scriptInstPortOdfHilo.py con Visual Studio y nos aseguramos de que los siguientes parámetros estén correctos:
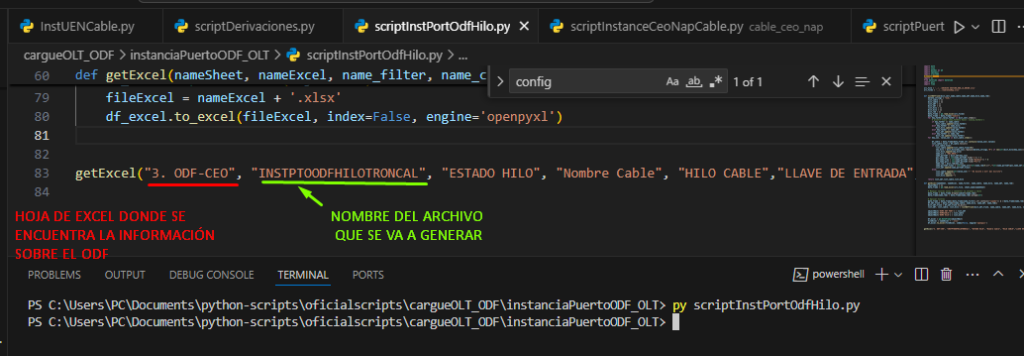
- HOJA DE EXCEL CON LA INFORMACIÓN: Es la hoja en la cual se encuentra la información de los puertos ODF.
- NOMBRE DE ARCHIVO GENERADO: es el nombre que va a tener el archivo de cargue
Ejecutar script: Una vez comprobado que los parametros estén correctos ejecutaremos el script desde la terminal de VS Code con el comando “py scriptInstPortOdfHilo.py” asegurándonos de estar en la ruta correcta (Ver Pag 4 – Pag 5)
Carga masiva: Una vez generados los archivos con la información de los puertos bandeja ODF y los Hilos Troncales, iremos a la vista de CARGA MASIVA en donde seleccionaremos la lista “Puerto ODF / HILO Troncal Instancia LU” realizaremos la instancia de la información (Ver, Pag 6 – Pag 7)
- SCRIPT PUERTO ODF – PUERTO OLT
Abrimos nuestro archivo scriptInstPortOdfPortOLT.py con Visual Studio y nos aseguramos de que los siguientes parámetros estén correctos:
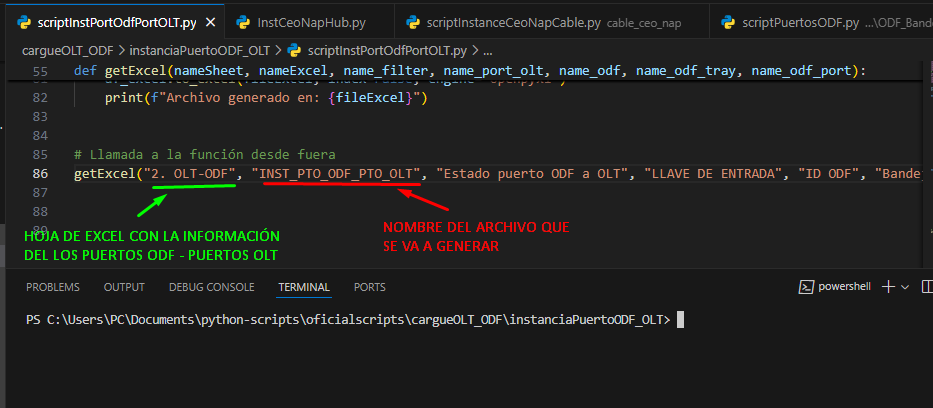
- HOJA DE EXCEL CON LA INFORMACIÓN: Es la hoja en la cual se encuentra la información de los puertos ODF – Puertos OLT.
- NOMBRE DE ARCHIVO GENERADO: es el nombre que va a tener el archivo de cargue
Ejecutar script: Una vez comprobado que los parametros estén correctos ejecutaremos el script desde la terminal de VS Code con el comando “py scriptInstPortOdfPortOLT.py” asegurándonos de estar en la ruta correcta (Ver Pag 4 – Pag 5)
Carga masiva: Una vez generados los archivos con la información de los puertos bandeja ODF y los puertos tarjetas OLT, iremos a la vista de CARGA MASIVA en donde seleccionaremos la lista “Instancia Puerto OLT / Puerto ODF LU” realizaremos la instancia de la información (Ver, Pag 6 – Pag 7)
5.12 SCRIPT INSTANCIA UEN – NAP, UEN – CEO, UEN – HUB:
Abrimos nuestro archivo InstCeoNapHub.py con Visual Studio y nos aseguramos de que los siguientes parámetros estén correctos:
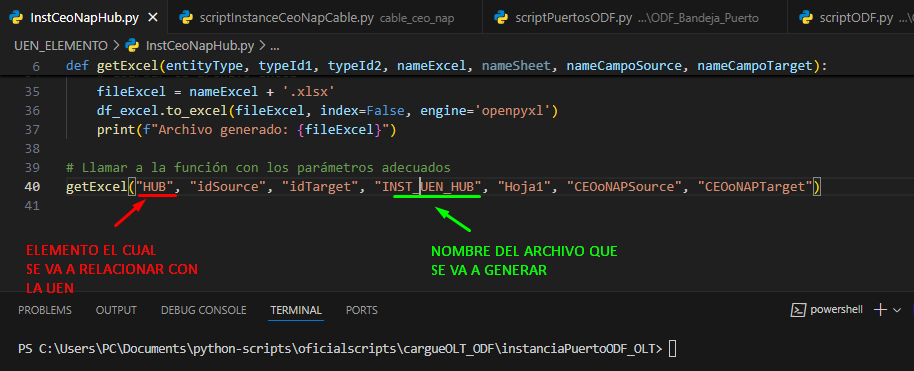
- ELEMENTOS PARA RELACIONAR CON LA UEN: En este parámetro debemos colocar el nombre de los elementos que vamos a relacionar con la UEN, es decir “HUB”, “NAP” Y “CEO” debemos ejecutar el script por cada uno de los anteriores.
- NOMBRE DE ARCHIVO GENERADO: es el nombre que va a tener el archivo de instancia este debe ser diferente para cada uno de los tres elementos.
Ejecutar script: Una vez comprobado que los parametros estén correctos ejecutaremos el script desde la terminal de VS Code con el comando “py InstCeoNapHub.py” asegurándonos de estar en la ruta correcta (Ver Pag 4 – Pag 5)
Carga masiva: Una vez generados los archivos con la información de los elementos y la UEN, iremos a la vista de CARGA MASIVA en donde seleccionaremos dependiendo de nuestros elementos “NAP” la lista “Instancia_UEN_Nap_LU”, “CEO“ la lista “Instancia UEN_CEO LU”realizaremos la instancia de la información (Ver, Pag 6 – Pag 7)